



Exposing the Truth About Zero-Day Deepfake Attacks

Elie Khoury
author • 5th July 2023 (UPDATED ON 01/17/2025)
8 minute read time
A lot has been written in the cyber security press recently about the declining efficacy of voice biometrics. The emergence of Artificial Intelligence (AI)-generated synthetic content has been frequently attributed as a critical threat to the reliability of voice-based authentication methods, casting doubts on its long-term viability. Call center teams have been concerned about the ability of deepfake detection tools to protect against attacks from previously unknown models that might launch potential zero-day attacks. Meta’s recent announcement of Voicebox1, a new AI model for generating synthetic audio, created an opportunity for Pindrop to test its tools against synthetic audio that Pindrop’s system was not trained on. Given Meta’s recent release of the audio content on June 16th, which had not been shared before, it can be considered as previously undisclosed, enabling us to effectively simulate a zero-day attack. This test allowed Pindrop to debunk some of the common myths surrounding voice biometrics.
Here’s what our experts discovered:
- Text-to-Speech (TTS) systems are built to make use of existing open-source components, making zero-day deepfakes much more difficult to execute.
- Zero-day deepfake attacks are less likely to fool voice authentication systems with liveness detection capabilities, like Pindrop.
- Voice authentication systems, especially when used as part of a multi-factor authentication strategy, continue to be a highly effective way to authenticate real users.
Why are voice biometric engines perceived to be vulnerable to zero-day attacks?
Voice biometric engines, like Pindrop, are Artificial Intelligence systems that assess the speaker voice similarity2 as well as the trustworthiness of the voice sample. Their countermeasure component is developed by training on both human and synthetic speech. Training data for these systems include synthetic audio generated from all known generative AI models. Customers and prospects have often asked, “Will Pindrop detect synthetic content it has not been trained on”?
This question is especially important as audio deepfake detection techniques, namely text-to-speech (TTS) and voice conversion (VC), have tremendously evolved in recent years thanks to the breakthrough in deep learning and generative Artificial intelligence. Such systems include ElevenLabs TTS, Microsoft’s VALL-E, and Meta’s Voicebox. This fast pace of developing speech synthesis systems has begged the question: are countermeasure systems able to detect unseen speech synthesis techniques in the scenario of a zero-day attack?
How do zero-day attacks work?
To better understand how a zero-day attack works we need to first understand the anatomy of a typical Text-to-Speech system or TTS that forms the core of a generative AI structure.
Anatomy of a Text-To-Speech (TTS) system
A modern TTS system is typically composed of three building blocks3: the text analysis conversion, the acoustic model, and the vocoder.

Figure 1. The three building blocks of a modern TTS system4.
Text analysis is the process of converting the input text into phonetic and linguistic features. Such features include phonemes, syllables, words, prosody, style, and emotional state. The acoustic model constitutes the machine learning algorithm that transforms the phonetic and linguistic features into acoustic features (e.g. Mel spectrograms, or discrete acoustic code). A large variety of Deep Neural Network (DNN) architectures has been adopted, but their backbones are often Convolutional Neural Networks (ConvNets), Recurrent Neural Networks (RNNs), Generative Adversarial Networks (GANs), or more recently Transformers. The vocoder aims to solve the inverse process of reconstructing the audio from the acoustic features. A vocoder could be Digital Signal Processing (DSP)-based (e.g. WORLD and STRAIGHT), or DNN-based (e.g. Wavenet, HiFi-GAN, and EnCodec).
Typically, when developing a new TTS system, a team usually focuses the innovation on a limited set of areas. As is increasingly common with modern software development, they leverage state-of-the-art capabilities where available, especially with the plethora of open-source options. This reduces the time and cost for researchers to improve upon existing approaches. As a result, not all of the above three components are modified simultaneously in recent TTS systems. For instance, Microsoft’s VALL-E uses the existing EnCodec vocoder5.
Similarly, Meta’s Voicebox uses the existing HiFi-GAN vocoder6. In addition to the artificial intelligence building blocks, TTS systems also rely on common DSP tools such as Librosa7 and DNN tools such as, pytorch8 or tensorflow9, which increases the similarity of their acoustic output and makes it easier to detect without prior training.
Developing a new TTS system from new components is more expensive, time-consuming, and complex than using an existing TTS or reusing existing components to assemble a new TTS.
Meta’s Voicebox generative AI
Meta introduced Voicebox on June 16, 2023. This new system achieved state-of-the-art performance on various TTS applications including editing, denoising, and cross-lingual TTS. The main success of such a system is attributed to the use of Flow Matching for Generative Modeling which outperforms diffusion models on computer-vision tasks. Additionally, the paper released by Meta details the use of the existing HiFi-GAN vocoder.
While this TTS system reached a close-to-human level quality of speech, Meta Researchers found that they can easily detect voicebox synthesized speech vs real speech when they train a simple binary classifier directly on data generated from Voicebox. But, what if hypothetically such a system was developed by bad actors, or what if bad actors got early access to Voicebox service and used it to attack voice biometric systems? Would they have a chance to succeed?
How Pindrop’s voice biometric and liveness detection system can stop zero-day attacks
To answer this question, we ran our most recent deepfake detection against all Voicebox samples (this includes the introductory video that was split into 3-second chunks). While our training data does not include any Voicebox samples, it was trained on old data that included three different variants of the HiFi-GAN vocoder. Interestingly, Pindrop’s deepfake detection system was able to detect 90% of the Voicebox samples10 when exposed to these samples for the first time. We believe that these are excellent results for a zero-day attack setup. Once our system learned more about this new TTS from limited samples available publicly, we were able to close the gap and reach an accuracy of over 99%11. This highlights the ability of strong deepfake detection tools to identify new synthetic speech engines like Voicebox.
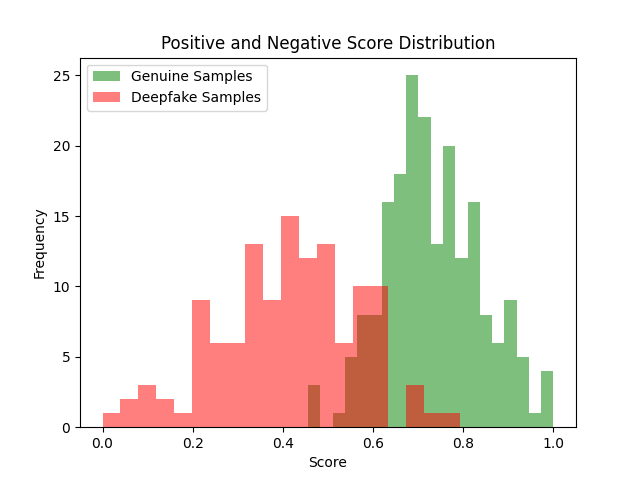
Figure 2. Histogram of the score distribution. The red color is the score distribution of the Voicebox TTS samples. The green color is the distribution of genuine samples randomly sampled from the Librispeech dataset. At a threshold of 0.65, our system is able to separate most of the spoof and genuine samples and achieves an overall accuracy of 90%.
Pindrop’s system is trained on a very large and diverse set of TTS and VC systems that cover most of the known combinations of techniques used in the three building blocks. This dataset enables Pindrop to detect previously unseen TTS systems with very high accuracy, especially when those systems reuse existing known components, such as VALL-E or Meta’s Voicebox. For fraudsters to pull off zero-day attacks with deepfakes against Pindrop, they will need to build their own TTS from new underlying components and not just use an existing TTS or assemble a new TTS from pre-existing components.
The question of whether voice biometric countermeasures are able to detect unseen speech synthesis techniques was also asked in ASVspoof 201912 Challenge where 11 TTS and VC systems, unseen during system development, were used in the evaluation set. Pindrop achieved the lowest equal error rate (EER) at the ASVspoof 2019 challenge in the category of single systems, which shows a high degree of generalization, establishing that Pindrop can indeed identify synthetic content it had not been trained on.
Beyond voice biometrics: a multi-layered approach to stopping deepfakes
Pindrop’s multi-factor security approach further raises the bar on fraudsters to pull off a deepfake attack. Pindrop leverages behavior analysis, Deviceprinting, carrier analysis, and caller ID spoof detection in addition to voice biometrics and liveness detection. To get past these layers, fraudsters will need to spoof the victim’s phone number, steal the victim’s device, and manipulate carrier metadata besides creating a high-quality voice fake from a new TTS without reusing components.
Key takeaways
It’s well known that bad actors are creative and constantly innovating with their generative speech and voice cloning attacks. However, the bar for them to create a zero-day attack with deepfakes is higher than what popular media articles would suggest. Having said that, deepfake detection systems are probabilistic models, and mathematically there is a non-zero probability of a fake not being detected. Pindrop’s vast & diverse training deepfake data set, the high accuracy of its deepfake detection algorithms, and its multi-factor approach make that much less likely than alternate approaches.
Finally, we would also like to acknowledge the impressive research team at Meta that included a binary classifier that is able to consistently distinguish between real speech and speech generated from their own TTS model. At Pindrop, we’re committed to working with all Generative AI systems to build an industry-standard approach to ethical and responsible AI.
1. https://voicebox.metademolab.com/
2. https://www.sciencedirect.com/science/article/abs/pii/S0167639309001289
3. As of June 2023, this dataset has about 6 millions samples covering various deepfake types.
4. https://www.isca-speech.org/archive_v0/Odyssey_2020/pdfs/29.pdf
5. https://arxiv.org/pdf/2210.13438.pdf, https://medium.com/syncedreview/meet-meta-ais-encodec-a-sota-real-time-neural-model-for-high-fidelity-audio-compression-93668d13fde7
6. https://arxiv.org/pdf/2010.05646.pdf
7. https://librosa.org/
8. https://pytorch.org/
9. https://www.tensorflow.org/
10. This was conducted on a curated dataset composed of all public 123 Voicebox samples and 200 genuine samples from Librispeech.
11. This was conducted on an internally curated dataset of about 200k samples of both genuine and deepfake samples.
12. Automatic Speaker Detection and Spoofing Countermeasure Challenge. https://www.asvspoof.org/index2019.html